Ongoing Human Action Recognition with Motion Capture
Mathieu Barnachon, Saida Bouakaz, Boubakeur Boufama, Erwan Guillou, In Pattern Recognition, vol. 47, issue 1. 2014.
Ongoing human action recognition is a challenging problem that has many applications, such as video surveillance, patient monitoring, human-computer interaction, etc. This paper presents a novel framework for recognizing streamed actions using Motion Capture (MoCap) data. Unlike the after-the-fact classification of completed activities, this work aims at achieving early recognition of ongoing activities. The proposed method is time efficient as it is based on histograms of action poses, extracted from MoCap data, that are computed according to Hausdorff distance. The histograms are then compared with the Bhattacharyya distance and warped by a dynamic time warping process to achieve their optimal alignment. This process, implemented by our dynamic programming-based solution, has the advantage of allowing some stretching flexibility to accommodate for possible action length changes. We have shown the success and the effectiveness of our solution by testing it on large datasets and comparing it with several state-of-the-art methods. In particular, we were able to achieve excellent recognition rates that have outperformed many well known methods.
A Real-Time System for Motion Retrieval and Interpretation
Mathieu Barnachon, Saida Bouakaz, Boubakeur Boufama, Erwan Guillou, In Pattern Recognition Letters, Special Issue on Smart Approaches for Human Action Recognition, 2013.
This paper proposes a new examplar-based method for real-time human motion recognition using Motion Capture (MoCap) data. We have formalized streamed recognizable actions, coming from an online MoCap engine, into a motion graph that is similar to an animation motion graph. This graph is used as an automaton to recognize known actions as well as to add new ones. We have defined and used a spatio-temporal metric for similarity measurements to achieve more accurate feedbacks on classification. The proposed method has the advantage of being linear and incremental, making the recognition process very fast and the addition of a new action straightforward. Furthermore, actions can be recognized with a score even before they are fully completed. Thanks to the use of a skeleton-centric coordinate system, our recognition method has become view-invariant. We have successfully tested our action recognition method on both synthetic and real data. We have also compared our results with four state-of-the-art methods using three well known datasets for human action recognition. In particular, the comparisons have clearly shown the advantage of our method through better recognition rates.
Human Actions Recognition from Streamed Motion Capture
Mathieu Barnachon, Saida Bouakaz, Boubakeur Boufama, Erwan Guillou, In ICPR 2012, Tsukuba.
This paper introduces a new method for streamed action recognition using Motion Capture (MoCap) data. First, the histograms of action poses, extracted from MoCap data, are computed according to Hausdorf distance. Then, using a dynamic programming algorithm and an incremental histogram computation, our proposed solution recognizes actions in real time from streams of poses. The comparison of histograms for recognition was achieved using Bhattacharyya distance. Furthermore, the learning phase has remained very efficient with respect to both time and complexity. We have shown the effectiveness of our solution by testing it on large datasets, obtained from animation databases. In particular, we were able to achieve excellent recognition rates that have outperformed the existing methods.


Intelligent Interactions Based on Motion
M. Barnachon, M. Ceccaroli, A. Cordier, E Guillou, M.Lefevre, In Workshop CBR and Games, ICCBR 2011, London.
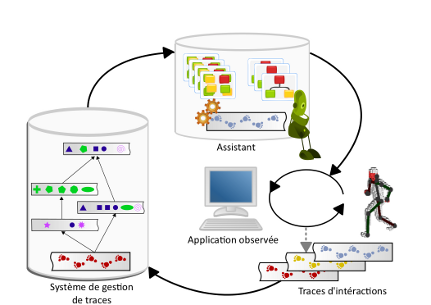
This paper introduces a project called iibm (Intelligent Interactions Based on Motion). In this project, we address the question of how to design and develop intelligent software systems controllable by gestures. This work is related to the eld of natural interactions, but we are not only interested in the motion capture issues. We focus on human-computer interaction and we seek to support negotiation of meaning and co-construction of knowledge between the user and the system. The goal is to develop intelligent and adaptive systems easy to use, through gestures, by end users. For that purpose, we exploit the CBR paradigm. CBR enables us to capture users' experiences and to reuse them in order to provide relevant feedback and assistance. This position paper presents the main ideas of our approach and illustrates them with a first experiment made within our test bed environment, with the application iiAnnotate. The paper also discusses the benets and risks of applying our approach to video games.
Towards Removing Ghost-Components from Visual-Hull Estimations
Brice Michoud, Erwan Guillou, Saida Bouakaz, Mathieu Barnachon, Alexandre Meyer. In ICIG 2009, Xi'an
Shape from Silhouette (SFS) are methods used to estimate the 3D shape of objects from their silhouettes. The reconstructed shape, also called Visual Hull (V H), is the maximum volume which yields the silhouettes. As this volume is an upper bound, it contains objects and artifacts. Ghost connected components coming from artifacts are parts empty of real object. They provide non-pertinent data that interfere with many applications of SFS: motion capture, free-viewpoint rendering, etc. The more the object’s number increases, the more ghost-components appears. The problem is even worst with a small number of cameras. In this paper, we address the issue of detecting and removing ghost-components from any Visual Hull. Our method only needs cameras’ calibration and silhouette data. A formal description and several practical experimentation, show the efficiency of our approach. A comparison with previous methods underlines more accurate results, even using few cameras.
Real time action recognition from examplars
Ph.D. Thesis, Mathieu Barnachon
In the past years, new advances in numerical images and tools have interested users for these usages. These evolutions have changed user’s way of interaction with a computer: from touch to gesture, going through video games and home monitoring, to name a few. To be attractive and efficient, these methods need new methodology for human action recognition and interpretation. For now, these solutions have to be efficient, easy to use and opened to new actions adding. We can highlight three kinds of methods: Machine Learning methods, stochastic model-based methods and examplar paradigm-based methods. The works presented in this thesis are related to the examplar paradigm, where the training is made with few instances. This choice allows to tackle huge database for training, and proposes a solution to recognize ongoing actions. We propose two complementary solutions, with real-time, precision and extensible constraints.
In the first hand, we analyse trajectories of articulations. Each articulation is associated to its trajectory along the action. We study changes in trajectories to propose a model of quantitative changes. These changes are considered as critical points for actions. Trajectories are then decomposed in segments to determine atomic parts of the action. This decomposition is used to create states in an automaton. These states are evaluated during the recognition process to identify action in progress. The recognition process of an action is modeled as an automaton path evaluation. One of the major advantages is that elements are spatio-temporally situated. The automaton gives a semantic organization of actions but it is sensitive to noise. Noise is coming from capture environment, characteristics extractions, or human motion variations.
In order to be insensitive to local trajectories variations, our second main contribution presented in this dissertation is dealing with invariant sequences in actions. We exploit the statistical redundancy of poses. Inspired by the Bag of Word approach, we have formalised delegates of poses, where each pose can be represented by its delegates. The frequency of each delegate is computed, by action, to construct an histogram of poses. Histograms are an efficient tool for representation, nevertheless, it suppresses the temporal component of action. As example, ``Stand-up'' action and ``Sit-down'' action have the same histogram. To deal with temporal relation involved in action, we have extended the integral histograms principle. These integral histograms are made from a partition according to time of the complete histogram. The better partition is made by a dynamical programming algorithm, inspired by Dynamic Time Warping. This solution is robust to noise despite that it lacks semantical representation.
Reconnaissance d'Action à Partir de Capture de Mouvements
Mathieu Barnachon, Saida Bouakaz, Boubakeur Boufama, Erwan Guillou, In Coresa 2012, Lille.
Cet article présente une méthode de reconnaissance des actions à partir de données issues de Capture de Mouvements (MoCap). Notre but est de réaliser cette tâche en temps réel, et sans recours à une base d’apprentissage lourde. Notre approche s’efforce de reconnaître une action au cours de son déroulement. Pour cela, nous calculons un histogramme des poses de MoCap pour chaque action. Cet histogramme est construit à partir d’une distance entre les poses, et nous comparons les histogrammes ainsi créés à l’aide de la distance de Bhattacharyya. Grâce à un algorithme de programmation dynamique, ainsi qu’à une construction incrémentale de notre histogramme, nous sommes en mesure de reconnaître des actions à partir d’un flux de capture de mouvements. Nous présentons les résultats d’expérimentations sur des données de synthèse, provenant de la base de MoCap de CMU, complétées par des données réelles, issues du dispositif Kinect. Les résultats obtenus montrent l’efficacité de notre méthode.
Interprétation de Mouvements Temps Réel
Mathieu Barnachon, Saida Bouakaz, Erwan Guillou, Boubakeur Boufama, In RFIA 2012, Lyon.
This paper proposes a new method for real-time human motion recognition using Motion Capture (MoCap) data. In particular, our method uses examplars to learn actions, without the need for learning intra class variations. We have formalized streamed recognizable actions, coming from an online MoCap engine, into a motion graph, similar to an animation motion graph. This graph is used as an automaton to recognize known actions as well as to add new ones. We have defined and used a spatio-temporal metric for similarity measurements to achieve more accurate feedbacks on classification. The proposed method has the advantage of being linear and incremental, making the recognition process very fast and the addition of a new action straightforward. Furthermore, actions can be recognized with a score, even before they are fully completed. Thanks to the use of a skeleton-centric coordinate system, our recognition method has become view-invariant. We have successfully tested our action recognition method on both synthetic and real data. The latter was obtained from live input videos using either our online markerless MoCap engine or the Kinect acquisition system.
Interactions Intelligentes à Base de Mouvements
M. Barnachon, M. Ceccaroli, A. Cordier, E Guillou, M. Lefevre, In Interaction Homme-Machine pour l'Apprentissage Humain (IHMA), Atelier de RFIA 2012, Lyon. 2012
Cet article présente une méthode de reconnaissance des actions à partir de données issues de Capture de Mouvements (MoCap). Notre but est de réaliser cette tâche en temps réel, et sans recours à une base d’apprentissage lourde. Notre approche s’efforce de reconnaître une action au cours de son déroulement. Pour cela, nous calculons un histogramme des poses de MoCap pour chaque action. Cet histogramme est construit à partir d’une distance entre les poses, et nous comparons les histogrammes ainsi créés à l’aide de la distance de Bhattacharyya. Grâce à un algorithme de programmation dynamique, ainsi qu’à une construction incrémentale de notre histogramme, nous sommes en mesure de reconnaître des actions à partir d’un flux de capture de mouvements. Nous présentons les résultats d’expérimentations sur des données de synthèse, provenant de la base de MoCap de CMU, complétées par des données réelles, issues du dispositif Kinect. Les résultats obtenus montrent l’efficacité de notre méthode.
Reconstruction géométrique par estimation de posture
Mathieu Barnachon, Brice Michoud, Erwan Guillou, Saida Bouakaz. In ORASIS 2009, Trégastel
Geometrical reconstruction from multiple cameras can now concurrence classical reconstruction. Shape From Silhouette (SFS) is a method that estimates the Visual Hull, in real time from observed silhouette in each view. Despite the fact that SFS is really simple and robust, it produces ghost parts: a set of 3D points that does not belong to real objects. These parts can significantly disturb the precision and the realism of the 3D shape. In this paper, we suggest to use the motion estimation of people, getting from motion capture, in order to remove these ghost parts and refine geometry. By construction, SFS gives a 3D hull of the filmed person. If we transform the computed geometry from original pose to the current pose, the intersection of reconstruction and observed pose produces a more precise reconstruction than the classical SFS. In this work, we introduce a real time and incremental approach, which automatically refines the 3D reconstruction of the acquired object.
Reconstruction Géométrique et Photométrique Incrémentale d'un Personnage en Mouvement à partir de Séquences Vidéo
Mathieu Barnachon, Erwan Guillou, Brice Michoud. In AFIG 2008, Toulouse
Avec les progrès constants de la réalité virtuelle et augmentée, de plus en plus d'environnements de qualité sont créés. Pour peupler ses environnements, il est nécessaire d'avoir des avatars brillants de réalisme. Les méthodes de Shape from Silhouette volumique permettent d'obtenir une ébauche de surface lors de l'enregistrement vidéo d'un sujet à partir de plusieurs caméras. Partant de cette représentation voxélique, on se propose de fournir la surface d'un modèle, à l'aide notamment du Marching Cubes. Pour des raisons évidentes d'efficacité, la reconstruction doit être incrémentale. Une technique de skinning permettra la génération d'un modèle générique dans une pose quelconque. Cela permet aussi d'affiner le modèle au cours du temps lorsque des parties auparavant invisibles rentrent dans le champs des caméras. La méthode se veut automatique, se contentant d'une reconstruction voxélique, et d'une estimation du mouvement d'un squelette humain -- sous forme de fichiers BVH, ou de positions des articulations -- pour fournir une surface d'une grande finesse. Une lecture des images des caméras permet d'obtenir les textures aux endroits reconstruits. Une approche dépendante du point de vue virtuel se propose d'utiliser la texture la plus adaptée. Le résultat en sortie est donc un avatar d'une surface assez précise -- même avec des données bruitées -- et texturée comme le modèle initial. L'ensemble de la méthode fonctionne en temps réel, en augmentant la précision des données en entrée.